This post is about modelling Talos data with a probabilistic model which can be applied to different use-cases, like detecting regressions and/or improvements over time.
Talos is Mozilla’s multiplatform performance testing framework written in python that we use to run and collect statistics of different performance tests after a push.
As a concrete example, this is how the performance data of a test might look like over time:
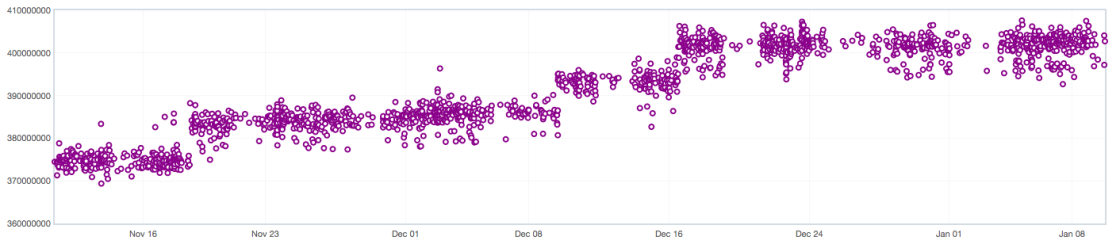
Even though there is some noise, which is exacerbated in this graph as the vertical axis doesn’t start from 0, we clearly see a shift of the distribution over time. We would like to detect such shifts as soon as possible after they happened.
Talos data has been known for a while to generate in some cases bi-modal data points that can break our current alerting engine.
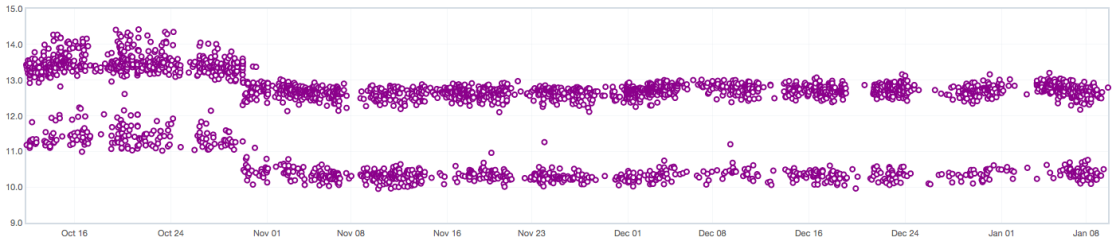
Possible reasons for bi-modality are documented in Bug 908888. As past efforts to remove the bi-modal behavior at the source have failed we have to deal with it in our model.
The following are some notes originated from conversations with Joel, Kyle, Mauro and Saptarshi.
Mixture of Gaussians
The data can be modelled as a mixture of 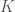
The first obstacle is to estimate the parameters of the mixture from a set of data points. Let’s state this problem formally; if you are not interested in the mathematical derivation it suffices to know that scikit-learn has an efficient implementation of it.
EM Algorithm
We want to find the probability density 



where 
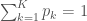
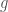
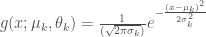
Now, given a set of 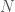

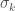

To find a maximum of 
![\frac{\partial{g(x_i; \mu_k, \theta_k)}}{\partial{\mu_k}} = g(x_i; \mu_k, \theta_k) \frac{\partial}{\partial{\mu_k}} [-\frac{(x_i - \mu_k)^2}{2\sigma_k^2}] = \frac{g(x_i; \mu_k, \theta_k) (x_i - \mu_k)}{\sigma_k^2}](https://s0.wp.com/latex.php?latex=%5Cfrac%7B%5Cpartial%7Bg%28x_i%3B+%5Cmu_k%2C+%5Ctheta_k%29%7D%7D%7B%5Cpartial%7B%5Cmu_k%7D%7D+%3D+g%28x_i%3B+%5Cmu_k%2C+%5Ctheta_k%29+%5Cfrac%7B%5Cpartial%7D%7B%5Cpartial%7B%5Cmu_k%7D%7D+%5B-%5Cfrac%7B%28x_i+-+%5Cmu_k%29%5E2%7D%7B2%5Csigma_k%5E2%7D%5D+%3D+%5Cfrac%7Bg%28x_i%3B+%5Cmu_k%2C+%5Ctheta_k%29+%28x_i+-+%5Cmu_k%29%7D%7B%5Csigma_k%5E2%7D+&bg=ffffff&fg=444444&s=0&c=20201002)
then
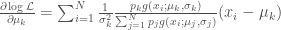
But, by Bayes’ Theorem, 




By applying a similar procedure to compute the partial derivative with respect to

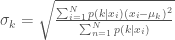
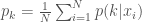
The first two equations turn out to be simply the sample mean and standard deviation of the data weighted by the conditional probability that component
Since the terms
E Step

M Step
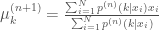
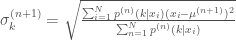
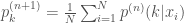
Intuitively, in the E-step the parameters of the components are assumed to be given and the data points are soft-assigned to the clusters. In the M-step we compute the updated parameters for our clusters given the new assignment.
Determine K
Now that we have a way to fit a mixture of
Regression Detection
A simple approach to detect changes in the series is to use a rolling window and compare the distribution of the first half of the window to the distribution of the second half. Since we are dealing with Gaussians, we can use the z-statistic to compare the mean of each component in the left window to mean of its corresponding component in the right window:

In the following plots the red dots are points at which the regression detection would have fired. Ideally the system would generate a single alert per cluster for the first point after the distribution shift.
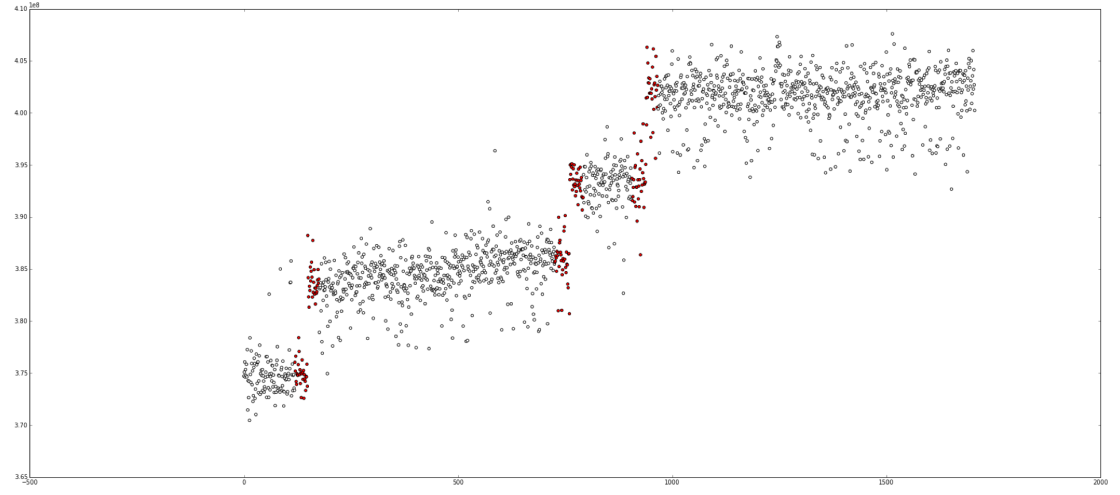

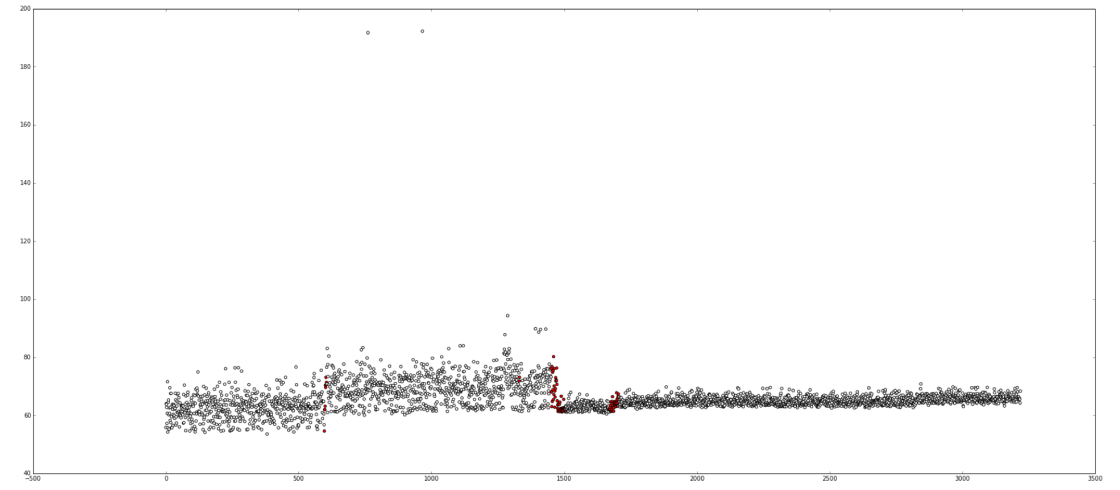
Talos generates hundreds of different time series, some with dominating and peculiar noise patterns. As such it’s hard to come up with a generic model that solves the problem for good and represents the data perfectly.
Since the API to access this data is public, it provides an exciting opportunity for a contributor to come up with better ways of representing it. Feel free to join us on #perf if you are interested. Oh and, did I mentions we are hiring a Senior Data Engineer?





You must be logged in to post a comment.